头条搜索虽然还没有正式推出和上线 但派出的爬虫已让很多网站痛苦不堪
更新:头条搜索已经与蓝点网联系进行沟通,已经对本文提到的各类问题进行优化升级,后续头条搜索还将不断完善和迭代,努力为站长们提供更好的体验。如果后续发现其他问题或者有任何意见建议,站长和网站管理员们均可发送邮件到bytespider@bytedance.com进行反馈。
此前有消息指出字节跳动旗下的今日头条正在开发搜索引擎,目前头条搜索网页手机版已经可以访问和进行搜索。
虽然字节跳动官方尚未宣布今日头条通用搜索正式上线推出,不过头条搜索派出的爬虫已经让很多网站痛苦不堪。
因为头条搜索使用的爬虫毫无节制的抓爬网站耗费网站的服务器和带宽资源,部分配置较低的网站已经直接瘫痪。
蓝点网在帮朋友网站处理访问异常时便以为是遭遇攻击 , 但排查日志发现名为 ByteSpider 的爬虫才是罪魁祸首。
这个爬虫程序便是字节跳动旗下今日头条搜索的,其抓爬频率每秒几十次甚至高达数百次严重影响网站正常访问。
正常情况下搜索引擎爬虫会根据网站实际访问性能来进行抓取,即动态调整抓爬频率不会导致网站出现异常情况。
显然头条搜索不知道是了快速抓取全网内容还是存在技术问题,爬虫程序直接毫无节制的疯狂抓爬无视网站性能。

网站日志中出现的ByteSpider
正常的爬虫会在用户字符串信息里留下爬虫说明网址,网站管理员可根据其说明调整抓爬频率或进行屏蔽操作等。
而头条搜索的爬虫伪装成多种手机的字符串并且没有任何说明,其抓爬力度堪比多年前的Yisou Spider流氓爬虫。
注:Yisou Spider不是宜搜搜索的爬虫,这个爬虫在2015年前后因高频抓爬和不遵守robots.txt协议而人人喊打。
# 头条爬虫使用多种UA,包括三星/谷歌/苹果手机等(共有26个版本/UA) DYNAMIC|CHARGE|NOTLAST "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.5047.1291 Mobile Safari/537.36; Bytespider" DYNAMIC|CHARGE|NOTLAST "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.6154.1336 Mobile Safari/537.36; Bytespider" DYNAMIC|CHARGE|NOTLAST "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.6445.1813 Mobile Safari/537.36; Bytespider" DYNAMIC|CHARGE|NOTLAST "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.5916.1183 Mobile Safari/537.36; Bytespider"
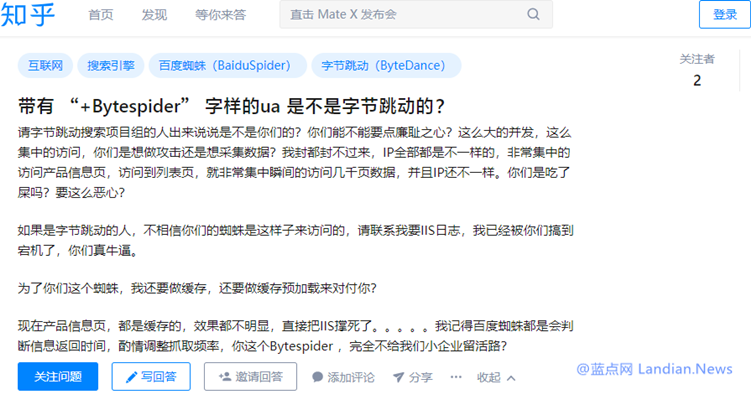
图片来源:知乎
头条爬虫的无节制疯狂抓爬导致网站服务器带宽和硬件资源大量浪费,而正常用户的访问变得缓慢甚至无法访问。
对于绝大多数小型网站和那些只是用来展示信息的企业网站来说,遇到头条爬虫只能增加成本提高带宽维持访问。
不过如果能够成功通过日志排查到是头条蜘蛛惹的祸,那么还可以使用多种策略将头条蜘蛛彻底屏蔽阻止其访问。
例如知名操作系统Debian在其讨论组网站就使用robots.txt规则屏蔽头条爬虫,不过也有用户反馈屏蔽没有作用。
因为头条爬虫可能不遵守robots.txt 规则无视封禁指令 , 头条网站目前同时向国内外大量网站开启疯狂抓爬模式。
在国内外技术讨论社区都出现各种抱怨的帖子 , 好在已经有网友统计出头条爬虫的IP端可以直接屏蔽IP端的访问。

图片来源:V2EX
鉴于国外开发者已经反馈头条爬虫不遵守 robots.txt 协议 , 因此我们在屏蔽该爬虫时不能只添加robots.txt封禁。
最佳做法包括在服务器上直接识别头条爬虫名称然后进行封禁,同时也可以在服务器上封禁头条爬虫的服务器等。
有条件的网站建议同时部署所有封禁策略防止部分策略不起作用或有漏网之鱼等等,具体几种封禁策略如下所述:
# 在robots.txt协议中封禁头条爬虫(不一定有用) User-agent: Bytespider Disallow: / # 在服务器上或者CDN节点上屏蔽头条爬虫IP段:(推荐) 110.249.202.0/24 110.249.201.0/24 111.225.149.0/24 111.225.148.0/24 #新添加头条爬虫IP段请一并加入屏蔽列表 220.243.135.0/24 220.243.136.0/24 # Nginx服务器可参考此地址封禁头条爬虫UA:(推荐) https://www.cnblogs.com/itsharehome/p/11114588.html # 使用宝塔面板的用户亦可直接在宝塔面板的UA黑名单中屏蔽以下关键词 Bytespider
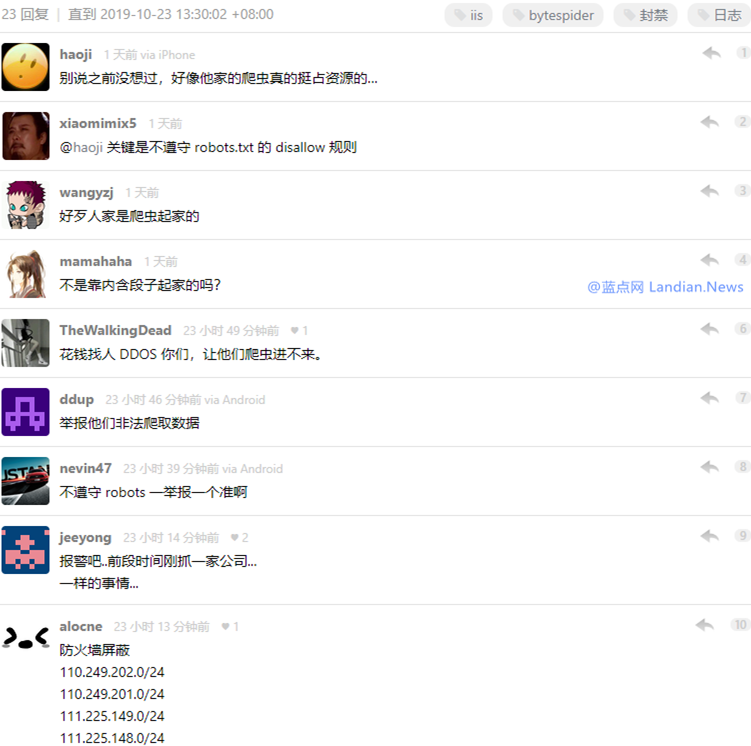
图片来源:V2EX