CloudFlare发布大规模中断事故报告:“鬼知道怎么一到生产环境就挂了”
CloudFlare今天发生大规模中断,由于相当多的网站托管在CloudFlare因此中午的时候很多用户访问这些网站出现500错误,现在CloudFlare已经发布事故报告。
作为主要基础设施提供商CloudFlare的每次中断都有不同的原因,当然标题只是开个玩笑,此次中断是CloudFlare调整配置引起的,有点类似你在生产环境修改个配置文件,本来本地测试已经没问题了,鬼知道一到生产环境上怎么就挂了。
CloudFlare的本意是准备升级网状网络 — 一种更有弹性的架构,方便工程师快速禁用某个数据中心的某一部分进行维护,前端访问会瞬间切换到其他部分不会影响访问,对CloudFlare来说升级这个名为MCP架构后对未来的升级和维护具有重大意义。
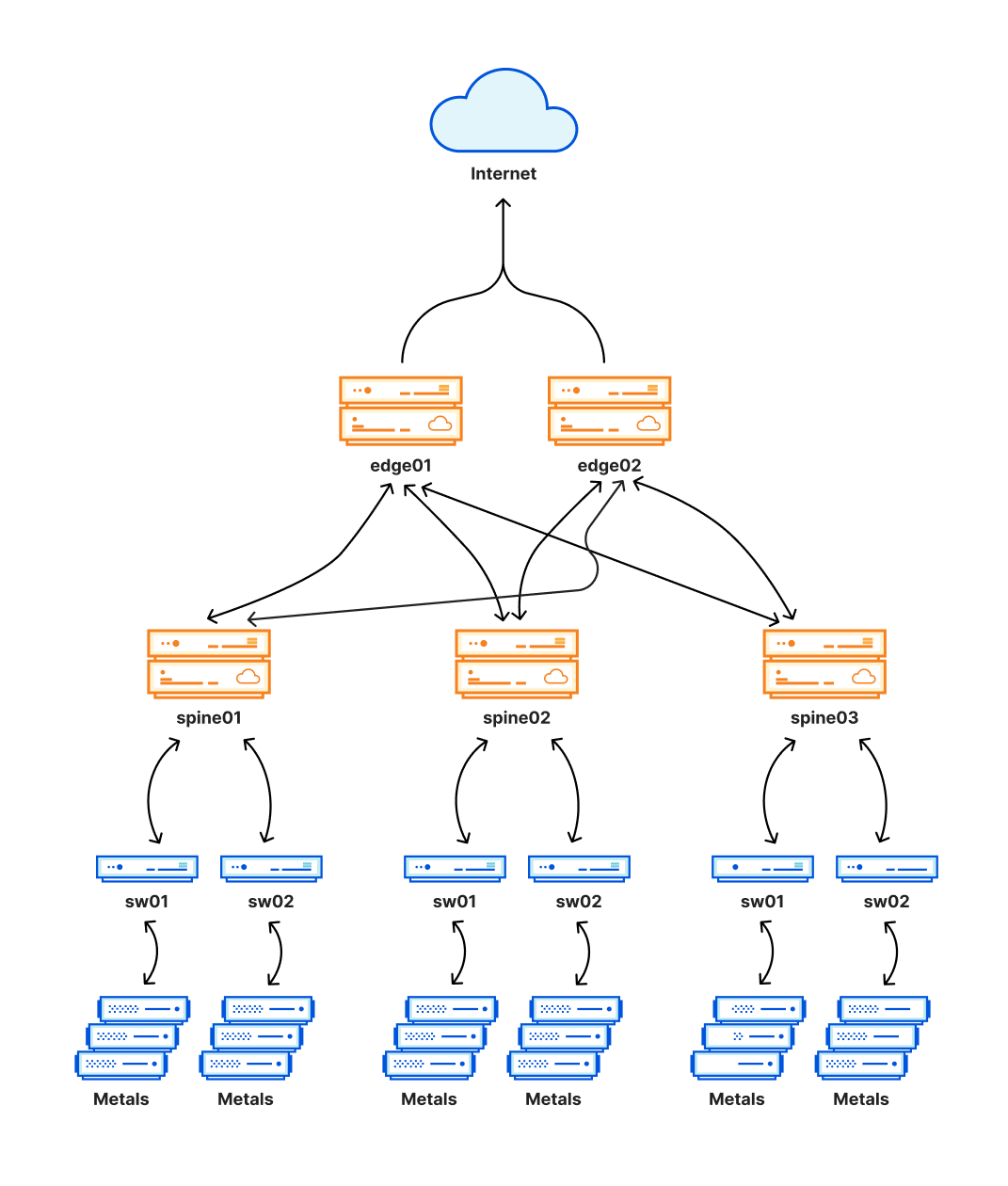
目前已经成功升级的数据中心包括阿姆斯特丹、亚特兰大、阿什本、芝加哥、法兰克福、伦敦、洛杉矶、马德里、曼彻斯特、迈阿密、米兰、孟买、新加坡、东京等。
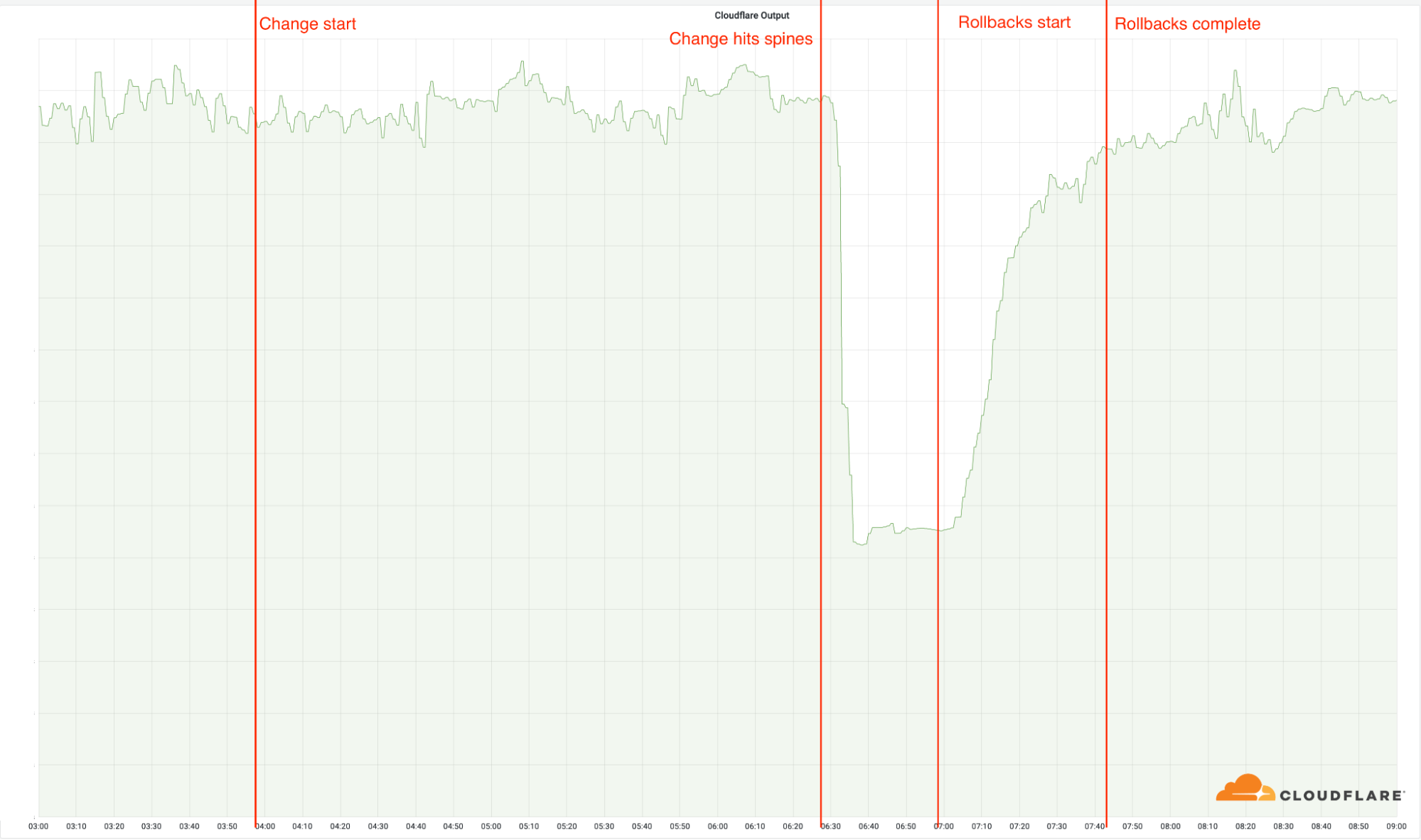
但今天在部署更新的时候很多服务器IP被撤回,这些IP地址在互联网上无法访问,为什么出现这个问题呢?因为IP地址集被通告时遭遇故障,导致这些IP被撤回。
CloudFlare工程师很快就发现问题,但难以恢复,当时超过19个数据中心离线,随后工程师进行验证并找到问题根源,然后就是通过备份恢复架构,直到最后还原完成工程师检查各个数据中心都OK后事件结束。
目前这些数据中心并未完成架构升级,估计后面排查问题后CloudFlare还要再此尝试升级,希望不会在大面积挂了。
一些数据:
受影响的这19个数据中心都是最繁忙的数据中心,19个数据中心占CloudFlare总数据中心的4%,但总流量占比高达50%,这些数据中心基本都是各个大洲或区域的主要数据中心,例如亚洲附近的日本东京数据中心、日本大阪数据中心、新加坡数据中心、印度孟买数据中心等。故障发生后CloudFlare的流量也直接跌了一半。